Editorial
 Several of the articles in this Newsleter were inspired either by
comments made on the PL/I newsgroup comp.lang.pl1 or by discussion
on that newsgroup.
Several of the articles in this Newsleter were inspired either by
comments made on the PL/I newsgroup comp.lang.pl1 or by discussion
on that newsgroup.
The discussion made the author realize that PL/I is capable of much more than first appears – namely, that it is able to emulate other languages at the source level, and to to provide new syntax for a completely new feature.
One such facility is the Fortran construct X(J:K) which refers to elements X(J) through X(K) of array X. An equivalent facility may be implemented in PL/I.
Read on to find out how.
Fractal by Lee H. Skinner, from the CD Fractal Frenzy: Visions of Chaos, Volume 1, Walnut Creek Software.
Please send any comments and contributions for the next newsletter to email: robin_v@bigpond.com
The third issue may be downloaded from: The PL/I Newsletter, No. 3, June 2001.
The second issue may be downloaded from: The PL/I Newsletter, No. 2, September 2000.
The first issue may be downloaded from: The PL/I Newsletter, No. 1, July 2000.
The summer 2000 edition of the
COBOL and PL/I newsletter
has some topics about PL/I. The specific PL/I
topics may be viewed separately.
Earlier editions of the newsletter in PDF format may be downloaded.
Editions of The PL/I Connection will be of interest.
Processing SMF Data in PL/I
by Peter Flass. Copyright © 2001 by Peter Flass.SMF (System Management Facilities) is IBM's data collection facility for accounting and performance data on MVS, OS/390, and z/OS. Although programs such as SAS, EPDM, and SLR eliminate much of the need to write programs to process SMF data there still may be times when programming is preferable.
In the June issue of the PL/I Newsletter, I introduced a program called UPTIME that processed SMF data to generate a graph of CICS availability. In that article I concentrated on generation of the graph and glossed over the data analysis. This article will look at the processing of the SMF data in more detail.
The current version of SMF stores data in entry-sequenced VSAM datatasets generally referred to as "SYS1.MAN" datasets. The data is stored as variable-length spanned records with a maximum record length of 32767 bytes. In our environment we copy these records to a sequential dataset for processing. SMF data is stored in what is known as "self-defining format", that is each record contains identifying information and pointers to groups or sections of related information. Sections can be expanded or new sections added without forcing changes in the programs that process the information. Programs written for much older releases will still run correctly with new versions of the data. This is the case with UPTIME, which was originally written in 1992 and still runs today with only minor changes.
The format of SMF records is well documented. Documentation for the latest version of SMF for z/OS 1.2.0 is available online. IBM provides macros to define the format of the various records in SYS1.MACLIB. Unfortunately only Assembler and PL/S, but not PL/I, definitions are provided. Recoding the definitions from PL/S to PL/I is relatively tedious but not difficult. The Macro IFASMFR provides the interface to map all the SMF records, a few directly and others by calling additional macros.
I am including a zip file containing all the SMF mapping macros used by UPTIME, plus others. PL/S used to be documented somewhat in the manual GC28-6794-00: GUIDE TO PL/S II, which is unfortunately no longer available. It would seem possible (hint) to write a program which would automatically translate most of PL/S data definitions to PL/I. Here is an example of conversion of PL/S to PL/I. (Note - I use PL/S to refer interchangably to the various versions of IBM's system programming language: PL/S, PL/S II, PL/AS, etc).
| Here is how the beginning of the "type 0" record looks in PL/S: |
DCL 1 SMFRCD00 BASED(SMF00PTR) BDY(WORD),
3 SMF0LEN FIXED(15), /* RDW RECORD LENGTH */
3 SMF0SEG FIXED(15), /* RDW SEGMENT DESCRIPTOR */
3 SMF0FLG BIT(8), /* OPERATING ENVIRONMENT */
3 SMF0RTY FIXED(8), /* RECORD TYPE 0 */
3 SMF0TME FIXED(31) BDY(HWORD), /* TOD RECORD WRITTEN */
3 SMF0DTE CHAR(4), /* DATE RECORD WRITTEN */
3 SMF0SID CHAR(4), /* SYSTEM ID FROM INSTALLATION */
...
|
| Here is a PL/I version; not much different: |
DCL 1 SMFRCD00 UNALIGNED BASED(SMF00PTR),
3 SMF0FLG BIT(8),
3 SMF0RTY BIT(8),
3 SMF0TME FIXED BIN(31),
3 SMF0DTE FIXED DEC(7),
3 SMF0SID CHAR(4),
...
|
The chief difference is that PL/S requires the definition of the variable-length-record headers which are handled automatically by PL/I (SMF0LEN and SMF0SEG). PL/S allows unsigned 8-bit fixed binary data (SMF0RTY) which has to be translated to BIT(8) for PL/I 2.3, although VisualAge PL/I should be able to handle it. PL/S does not have fixed decimal data (SMF0DTE); it uses char instead. Since I know from the documentation that this field is fixed decimal, I have defined it that way. The PL/S "BDY" attribute indicates alignment.
The fields above represent a standard header that is present in all SMF records. The remainder of the record is interpreted according to the record type SMF0RTY. There is a large number of different record formats; I haven't bothered to count, but the standard definitions go up to record type 120, with some gaps. IBM and other program products may also generate SMF records, which are documented with the product. For convenience I break out the fields above into a header definition I call "SMFC".
Here is how UPTIME processes the SMF data:
DCL SMFDATA INPUT RECORD;
ON ENDFILE(SMFDATA) EOF_SMF='1'B;
OPEN FILE(SMFDATA) INPUT;
READ FILE(SMFDATA) SET(SMFP);
DO WHILE(¬EOF_SMF);
SELECT(SMFXRTY); /* Process the SMF record */
WHEN(00) CALL IPL;
WHEN(23) CALL STATUS;
WHEN(30) CALL ADDR_SPACE;
OTHERWISE /* NULL */ ;
END; /* SELECT */
READ FILE(SMFDATA) SET(SMFP);
END; /* DO WHILE */
|
The processing routine for the SMF "type 30" record shows one method of parsing the self-defining records:
ADDR_SPACE: PROC;
ST = SMF30STP;
IF ST ¬= 1 & ST ¬= 5
THEN RETURN;
IF SMF30ION < 1 THEN RETURN;
|
The SMF documentation defines SMF30STP as a subtype code: in this case 1 is the code for a job start record, and 5 for a job termination.
The "type 30" record is a good example of a record that is broken down into subsections. I have found it easiest to define each subsection as a separate BASED structure. The base section contains the offsets from a specified point to each variable subsection. In this case SMF30IOF is defined to contain "Offset to identification subsection from the start of record, including RDW." The starting point may vary from record type to record type, so always check the documentation.
Since PL/I has skipped over the RDW (record descriptor word), and SMFP points to the first byte of data, the address of the identification section is computed by:
SMFP = PTRADD(SMFP,SMF30IOF-4); |
If I had it to do over, I'd probably use another pointer here. In UPTIME I have to save and restore SMFP. In any case, SMFP now points to the beginning of the "identification section." The base section contains pointers for ten subsections, not all of which are necessarily used with each record subtype. Each subsection pointer is a triplet that contains the offset to the subsection, the length of the subsection, and the number of subsections. For subsections that occur a number of times a program can walk through the occurrences by locating the first occurrence as above, then adding the length to the pointer to advance to the next occurrence.
Each SMF record type may be slightly different, but the principle of parsing the record by pointer arithmetic will be the same, and the documentation is excellent. Programs can either use PTRADD as above, or use the LANGLVL(SPROG) compiler option to allow pointer arithmetic.
UPTIME only needs to identify jobs by jobname. It's enough to look at the first identification section since the jobname will be the same throughout. The jobname can then be pulled out and compared with a predefined list of jobs. This is easily done with:
TASK = SMF30JBN; |
With a little effort, processing SMF data in PL/I is easy and provides significantly more flexibility than standard reporting programs.
Producing Tables and Charts
by Robin Vowels. Copyright © 2001 by Robin Vowels.Because of the outstanding text-processing facilities of PL/I, it is possible to produce better reports than simple listings. A PL/I procedure can produce a document file in Microsoft Rich Text Format (RTF) – a portable format. The resultant document file can then be opened with a word processor such as Microsoft Word or Corel WordPerfect, and then printed. And naturally, once the RTF file has been opened, it may be saved in any of the available document formats, or the diagrams may be copied and pasted into another document. The RTF format is convenient to generate because it is a text file.
Table
In the first example, a table is produced. The procedure that produces the table receives only a matrix (two-dimensional array) as an argument. Scaling of the table is automatic. However, it is simple to alter the physical size of the table.
| 27,263.15 | 4,629.37 | 95.70 | 89.62 |
| 337.28 | 94.63 | 71.04 | 3.57 |
| 9,270.01 | 255.41 | 687.14 | 81.25 |
| Gross | Tax | Expenses | Miscellaneous | |
| January | 27,263.15 | 4,629.37 | 95.70 | 89.62 |
| February | 337.28 | 94.63 | 71.04 | 3.57 |
| March | 9,270.01 | 255.41 | 687.14 | 81.25 |
Bar Chart
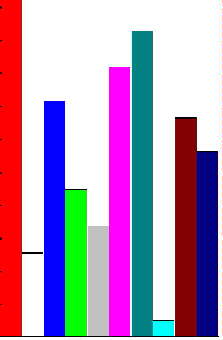 In this illustration, a colored bar chart is produced. The supplied
procedure accepts a one-dimensional array (a vector) as an argument.
Scaling of the chart to fit the page is automatic, as is the width of
each of the bars of the chart. It is a simple matter to change the
actual size of the chart. In any case, the size of the chart may be
changed once the document is opened by a word processor, in the usual
way by clicking on the chart and then dragging one of the resizing
handles.
In this illustration, a colored bar chart is produced. The supplied
procedure accepts a one-dimensional array (a vector) as an argument.
Scaling of the chart to fit the page is automatic, as is the width of
each of the bars of the chart. It is a simple matter to change the
actual size of the chart. In any case, the size of the chart may be
changed once the document is opened by a word processor, in the usual
way by clicking on the chart and then dragging one of the resizing
handles.
A miniature chart only is shown here, without footings (because the footings would be too small to read). In fact, a procedure also produces text footings for each column of the chart.
The bar chart is first produced as an image array. Four bits
correspond to each pixel, allowing for up to 14 colors, plus black
and white, and an image array of size 640 × 480 is produced.
The image array is effectively organized into vertical strips
corresponding to the bars of the chart, and part of each strip
(according to the magnitude of the corresponding element) is
initialized to a specific value corresponding to one of the colors.
When the initialization of the image array is complete, some
formatting commands are written into the RTF file, followed by the
image array as a bit-mapped file. The bit-mapped file appears in
text form, with each pixel being represented by the one of the
hexadecimal digits 0123456789ABCDEF.
Footings are then written out, as a table without borders,
which are synchronized with the columns of the chart.
The RTF closing command is
then written out to the RTF file.
Contact the author
for the source code.
A macro for initializing an array
by R. A. VowelsIn PL/I it is possible to initialize an array using the INITIAL attribute. However, only constants and expressions may be used as initial values.
From time to time, an array needs to be initialized to values that change systematically, for example, the values 1, 4, 9, 16, 25, etc. or the values 1, 2, 3, 4, 5, 6, 7, etc.
For a large array, it would be impractical to write out the values by hand. Of course, a loop could be written to generate the values at run time. For a STATIC array, however, where the values are needed for storage during compilation, this option is not appropriate.
PL/I's macro processor – perhaps overlooked as a convenient tool – can provide considerable help.
The accompanying code implements a facility to generate the values using an iterative DO. Examples of usage follow:
The (new) Built-in Functions of IBM VisualAge PL/I
by Robin VowelsIn this article, the author continues with a look at the (new) built-in functions of IBM VisualAge PL/I. (The article will be concluded in the next issue.)
-
ALLOCATE(n) allocates storage of size n and returns
a pointer to that storage.
- AVAILABLEAREA(x) returns the size of the largest contiguous area of memory that would be available for allocation from the area x.
- BITLOCATION(x) returns the location (in the range 0 to 7) of x within the byte where x is stored. (x is UNALIGNED BIT.)
- CHARGRAPHIC converts the argument from GRAPHIC to a mixed string. A length for the result may be specified.
- COLLATE returns a CHARACTER string of length 256 containing each of the characters in collating sequence order - 00h to FFh from left to right.
-
COMPARE(s1, s2, length) compares
length bytes at location s1 with those at s2.
The value returned (FIXED BINARY) is negative when
s1 < s2, zero when s1 = s2, and positive when s1 > s2.
The function is typically used when it is necessary to test two strings for less than, equal, and greater than, because is avoids the need to re-comparing the operands.
Note that s1 and s2 must have POINTER or OFFSET type.
Note also that these functions should be used only for CHARACTER data, as unexpected results may be obtained for CHARGRAPHIC data. For CHARGRAPHIC data, perform comparisons using the usual operators >, >=, etc, in which comparisons are performed on a symbol-by-symbol basis. - COPY(S, n) returns n copies of string S, joined together as a single string. The function differs from REPEAT and in a way that is more convenient. If n is zero, a null string is returned.
- CURRENTSIZE(x) returns the number of bytes of storage required by the argument x.
-
EDIT(Value, picture_pattern) returns the value in the
form specified by the picture pattern.
e.g., EDIT (12.345, '9999.999') returns '0012.345' -
ENDFILE(filename) returns '1'B if the file is
positioned at the end, or '0'B otherwise.
If the file is not open, the ERROR condition is raised. -
Several functions assist in the manipulation of floating-point
values. They are:
- HUGE(x) returns the largest floating-point number
appropriate for the class of floating-point number x.
Note that there may be more than one format of floating-point number on some systems, and that each format may have a different largest number. -
TINY(x) returns the smallest floating-point number
appropriate for the class of floating-point number x.
Note that there may be more than one format of floating-point number on some systems, and that each format may have a different smallest number. - EPSILON(X) returns a floating-point value that is the difference between x and the next representable positive value when x is 1.0
- EXPONENT(X) returns the exponent E of the floating-point value X as a FIXED BINARY integer. E is specified by the relation r**(E-1) <= |X| <= r**E, where r is the radix of X.
- SCALE (x, n) returns x*r**n (where r is the radix of x) as a floating-point value. The function RADIX returns the radix of x.
- RADIX (x) returns the radix of x as an integer.
-
PRED(x) returns the next smaller floating-point
value than x.
The OVERFLOW condition will be raised when X is already a negative number having the greatest magnitude, that is, PRED(X) will raise the OVERFLOW condition when X = -HUGE(X).
Note that the UNDERFLOW condition will not be raised for PRED(X) when X = TINY(X), which yields 0.
Note also that the value at which OVERFLOW is raised depends on the precision with which X is stored (just as there are different values for HUGE and TINY depending on the precision of X). -
SUCC(x) returns the next larger floating-point
value than x. The OVERFLOW condition will be raised when
x is already the largest positive number.
Note that the UNDERFLOW condition will not be raised for SUCC(X) when X = -TINY(X), which yields 0.
Note also that the value at which OVERFLOW is raised depends on the precision with which X is stored (just as there are different values for HUGE and TINY depending on the precision of X). -
PLACES(X) returns the number of binary digits
used for storing the floating-point value x.
For the PC, these values are:
Binary digits FLOAT DECIMAL ( 1) to FLOAT DECIMAL ( 6) 24 FLOAT DECIMAL ( 7) to FLOAT DECIMAL (16) 53 FLOAT DECIMAL (17) and more: 64 FLOAT BINARY ( 1) to FLOAT BINARY (21) 24 FLOAT BINARY (22) to FLOAT BINARY (53) 53 FLOAT BINARY (54) and above 64 - MINEXP(x) returns the smallest exponent that a floating-point value of the same form as x could take.
- MAXEXP(x) returns the largest exponent that a floating-point value of the same form as x could take.
- HUGE(x) returns the largest floating-point number
appropriate for the class of floating-point number x.
- FILEOPEN(filename) returns '1'B if the file filename is open, and '0'B otherwise.
- GAMMA(X) returns an approximation to the Gamma function of X.
- LOGGAMMA(X) returns the logarithm of the approximation to the Gamma function of X.
- HANDLE(x) returns a handle to the typed structure x.
-
HEX(x) returns a character string being the
hexadecimal form of the storage occupied by x.
It is not an exact
representation of memory. See also HEXIMAGE.
HEX(x, c) is the same as the one-argument version, except that the character c is inserted after every group of eight characters. -
HEXIMAGE(x, n) returns a character string being the
hexadecimal form of the n bytes of storage occupied
by x.
HEXIMAGE(x, n, c) is the same as the two-argument version, except that the character c is inserted after every group of eight characters. -
MAXLENGTH(x) returns the maximum length of a
string. It is normally intended to be used with varying-length
strings, but may also be used with fixed-length strings.
DECLARE S CHARACTER (10) VARYING INITIAL ('ONE'); L = LENGTH (S); /* Yields 3 */ L = MAXLENGTH (S); /* Yields 10 */ It is of particular use on an argument in a subroutine or function when that argument is varying-length. -
PL/I has facilities for ordinals, supported by several
built-in functions.
The following statements would define a set and initialize
the variable Direction to the member South.
DEFINE ORDINAL Compass (North, South, East, West); DECLARE Direction TYPE Compass; Direction = South; ORDINALPRED (Direction) yields North;
ORDINALSUCC (Direction) yields East.
ORDINALNAME (Direction) yields 'South'.
LAST (:Compass:) yields West.
FIRST (:Compass:) yields North.
The functions are explained below:- ORDINALNAME (X) returns the name of the member of the set of ordinals with which X is currently associated. Thus, the member's name may be printed.
- ORDINALPRED (X) returns the next lower member to ordinal X in the set in which X exists.
- ORDINALSUCC (X) returns the next higher member to ordinal X.
- FIRST (:Y:) returns the first ordinal in the set.
- LAST (:Y:) returns the last ordinal in the set.
DO Direction = FIRST (:Compass:) REPEAT ORDINALSUCC (Direction) UNTIL (Direction = LAST (:Compass:)); would be required. The following would print all the names of the members of the set (variables are as defined above):DO Direction = FIRST (:Compass:) REPEAT ORDINALSUCC (Direction) UNTIL (Direction = LAST (:Compass:)); PUT SKIP LIST (ORDINALNAME (Direction)); END; as follows:NORTH SOUTH EAST WEST - PAGENO (F) returns the current page number of the print file F.
-
TALLY: Need to count the number of times that a given
letter
appears in a sentence? or the number of times a word appears,
or any given group of characters? Then TALLY is for you!
TALLY(S, T) counts the number of times that string T appears in string S. S and T can be CHARACTER, BIT, or GRAPHIC. -
Ever groaned when a program issues an error message, and
you don't recall (or even know) which procedure contains the
corresponding PUT statement?
Then here's what you've been waiting for!
Several new functions assist in navigating one's way around a program. For example, any error messages written out by your program could display both the current procedure and the line number:
PUT SKIP LIST ('The data value ' || Value || ' is invalid. Noted in procedure ' || PROCEDURENAME || ' at line ' || SOURCELINE );
(Do remember to declare the built-in functions if used this way.)
The functions are:- PACKAGENAME returns the name of the package in which the current statement resides.
- PROCEDURENAME returns the name of the procedure in which the current statement resides;
- SOURCELINE returns the source line number of the current statement (relative to the start of the procedure).
- SOURCEFILE returns the name of the source file in which the current line resides.
-
VALID returns '1'B if the argument is a valid
FIXED DECIMAL value. It also returns '1'B if the argument
is a valid PICTURE value for its declaration. For invalid
values, '0'B is returned.
This function is useful for checking values that have been read in using a READ statement (the values of which are not checked on reading in).
Usefulle Webbe Lynx ...
-
IBM Announcement
In November 2001, IBM announced a new version of the PL/I compiler, called IBM Enterprise PL/I for z/OS and OS/390 V3R1.Quoting from the announcement, key features are:
- Easier Java interoperability
- Extensible Markup Language (XML) parser
- Improved compatibility with prior IBM PL/I compilers
- Integrated CICS (R) preprocessor
- Integrated SQL preprocessor
-
Raincode Corporation
has recently released RainCode Roadmap for PL/I,
which produces documentation of PL/I programs in HTML format.
- Stuck for a definition? Take a look at the Dictionary of Algorithms and Data Structures.
Cool Codes
by Robin Vowels. Copyright © 2001 by Robin Vowels.When performing a whole array operation such as an assignment, considerable improvement can be effected when the array is of BIT strings.
Here are some timings for the following three assignments respectively (with the attributes as shown below):
BYO traceback
Need to find out name of the calling procedure? Or to do a traceback without invoking the error-handler? The following ideas may be of use:
The line number of the calling procedure may be treated in a similar way.
At any time during execution, the traceback may be activated
by calling procedure TRACEBACK.
Normally, it will be necessary to restore the traceback
before continuing. This is done by calling the procedure
RESTORE_TRACEBACK.
These are illustrated in the following program:
Brain Teasers
Eberhard's PL/I Problem
In the previous issue of the PL/I Newsletter I presented a problem which allowed to declare a variable having 2,000,000,000 bytes and to even print out the value of an element. An old hand, perhaps, remembered iSUB-defining, and came to the following solution:Why did I present this puzzle? The only reason is, as I mentioned in the previous issue, to point out that this wonderful PL/I feature is now available again in IBM's new compiler. I don't know any programming language where you can define your own index computation! That's one of PL/I's highlights: Do complex things in the declare statement and keep the executable code simple!
Only slightly more complex was the solution worked out by Ross Ringwood and Glenn Higgins from Ireland whom I want to congratulate on their submitted program.
This month's problem
The new puzzle is very easy to interpret by the compiler but somewhat complex to a human reader. Look at the following program:*process rules (nolaxqual);
Don't fail to notice the specification (B)! But even if you have run the program, do you know why the result is as it is? By the way, this puzzle first appeared in a newsletter of 1982 – requesting the same value as a program compiled by the new IBM compiler produces nowadays – of course!
Send your solutions to Eberhard, who will reveal all in the next Newsletter.
Picture Puzzles
What is the difference, if any, between the picture specification P'$$$,$$$V.99' and P'$$$,$$$.V99' ? and under what circumstances will the difference, if any, become apparent?And what is special about P'---,---' ?
Send your solutions to robin. (Answers next Newsletter.)